



![]() Today’s Cloud models are not designed for the fast volume, type and velocity of data that will be generated by IoT devices. Two years ago I attended a webinar from Andreesen Horowitz, Sr VC partner, Peter Levine, where he predicted the end of the cloud as we know it. He compared the move to and away from centralized cloud compute to decentralized edge compute with the move form centralized mainframe computing in the 60’s and 70’s to decentralized mini and client server computing in the 80’s and 90’s and to centralized and virtualized IT and Cloud compute at the beginning of the 21st century and decentralizing compute and storage again today and tomorrow because of IoT.
Today’s Cloud models are not designed for the fast volume, type and velocity of data that will be generated by IoT devices. Two years ago I attended a webinar from Andreesen Horowitz, Sr VC partner, Peter Levine, where he predicted the end of the cloud as we know it. He compared the move to and away from centralized cloud compute to decentralized edge compute with the move form centralized mainframe computing in the 60’s and 70’s to decentralized mini and client server computing in the 80’s and 90’s and to centralized and virtualized IT and Cloud compute at the beginning of the 21st century and decentralizing compute and storage again today and tomorrow because of IoT.
To get some perspective on what IoT can produce on data a few examples. A commercial airplane generates around 10TB of data for every half hour flight. An offshore oil rig produces up to 1 Tb a week. A self-driving vehicle produces 10Gb of data per mile. And as these devices rely on real time correction based on data that has been gathered, going back and forth to the cloud is not an option. Bandwidth latency is simply too high. Also these billions of new connected devices also represent countless new types of data, using numerous industrial protocols, not all being IP. Before this data can be send to the cloud for storage or analytics these need to be converted into IP at first. And last but not least government and industry regulations and privacy concerns may prohibit that certain types of IoT data is stored offsite. So the ideal place to analyze IoT data is as close to the devices that produce and act on that data. This called Fog Computing.
What is it? The fog server is basically an extension of the Cloud. It stretches the Cloud to be closer to the things that produce the data and receive instructions to act on IoT data. These systems that gather data and do analytics and give instructions back are called fog nodes. The smaller you can make them the closer they can be to the IoT devices themselves.
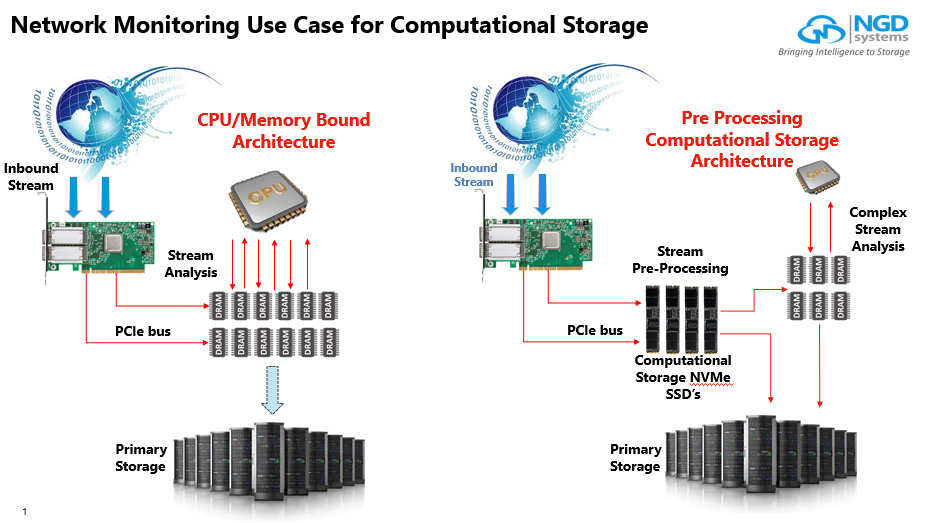
In Situ processing is designed to be at the heart of fog computing. In Situ processing means that it has compute power on the drive itself where the data is being stored in the first place. The data does not leave the drive it is originally stored on. After it is stored it can do analytics at the exact location where the data is stored without having to transport the data off the drive. It can make local judgement of what data it need to send back to the cloud for big data analyses, do the protocol conversion and also it can clean the disk and remove the stored IoT data once that data is no longer useful or valuable.
Fog computing gives the cloud the extension to be able to handle the vast amounts IoT data and allows only the valuable IoT data assets to be transported over IP back to the cloud for Analytics, Learning, Research and Archiving. In Situ processing is the vital component here since the IoT data does not have to travel, guaranteeing a safe journey in the fog with NVMestorage.com powered by NGD Systems’ Catalina In Situ processing NMVe technology.