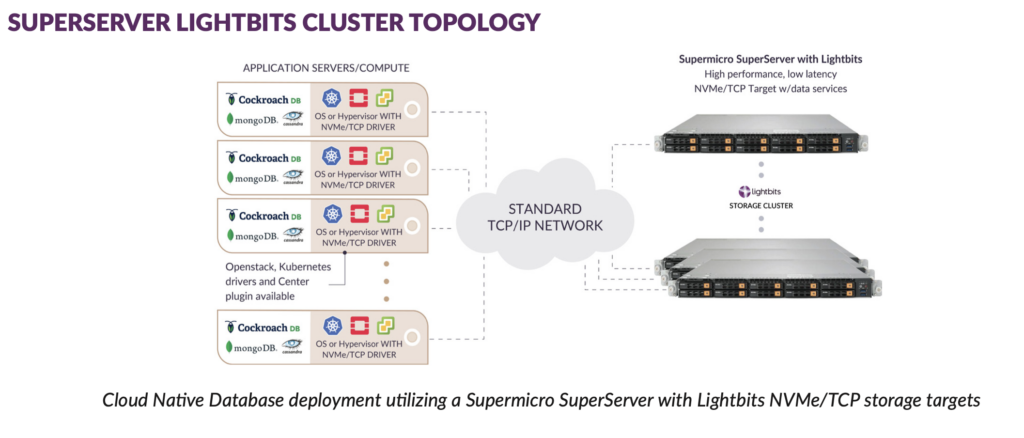
Lightbits’ software-defined, disaggregated and high-performance storage can be deployed on Supermicro SuperServers over standard ethernet networks using TCP/ IP protocol, requiring zero modification to applications.
While software-defined storage is desirable for its ability to lower cost by utilizing standard servers and components, a “do it yourself” approach is not for everyone.
For the ultimate in scalability, performance and convenience, this ready-to-deploy solution delivers composable NVMe® over TCP-based block storage with built- in Intelligent Flash ManagementTM that increases flash endurance by 20X. It’s an ideal platform for applications running on-premises, in private and edge clouds in containerized or virtual environments.
DEPLOYING WITH CONFIDENCE
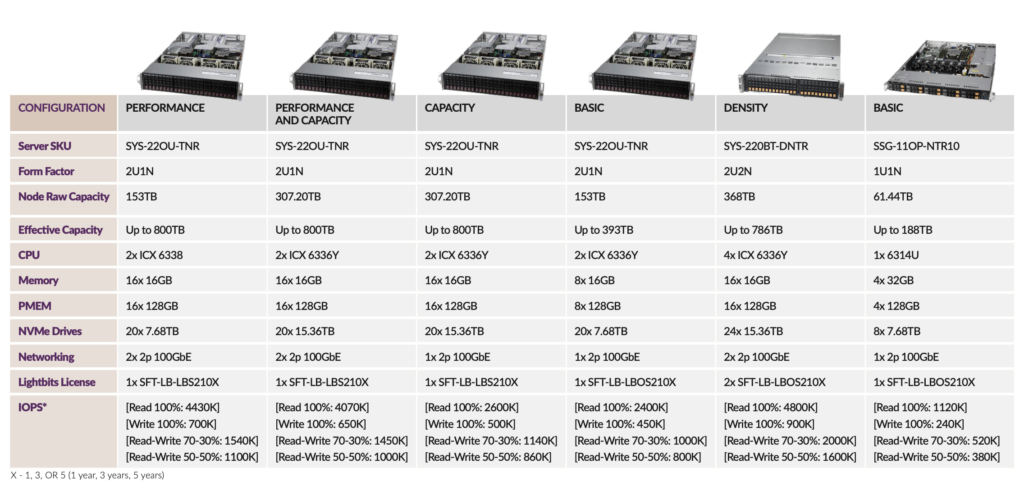
Lightbits offers rich data services such as thin provisioning and compression. A single SuperServer in a Lightbits cluster with redundancy enabled can serve up to 4.7 million random 4K read IOPs, up to 760,000 random 4K write IOPs, up to 21GB/s of read bandwidth and up to 4.3GB/s of write bandwidth.
- Unmodified Software on Clients
- Standard NVMeoF 1.1 w/multipathing (ANA)
- Clients can connect to multiple clusters
- Clustered/Failover Storage Solution
- Distributed cluster management with fast failover and no single point of failure
- Cluster size: 3-16 servers
- 64K Volumes per cluster
- Lightbits Cluster Performance
- 75 Million 4K Random Read IOPs
- 12 Million 4K Random Write IOPs
- 336 GB/s Read Bandwidth
- 68 GB/s Write Bandwidth
- Lightbits Cluster Capacity (15.36TB drives)
- 4.68PB Effective Capacity (2x
- replication, Elastic RAID, 2:1 compression)
- Lightbits Cluster Latency with
- 2x Replication
- 160μs average latency 4K Random
- Read @1.27M IOPs per server
- 493μs average latency 4K Random
- Write @433K IOPs per server
- Storage Services
- QoS
- Thin provisioning
- Compression
- Elastic RAID for drive failure protection
- Volume replication (1x, 2x or 3x) per volume
- Node Management
- Replication and failover handling • Failure handling using NVMe/TCP
- Multipath
- Non-disruptive cluster upgrades (for 2x and 3x replicated volumes)